
Executive Summary
In einem 72-Stunden-Fenster vom 21. bis 25. April 2026 lieferten OpenAI und Anthropic jeweils Produkte, die für sich genommen wie Leistungsupgrades erschienen, zusammen jedoch einen strukturellen Phasenwechsel in der Art darstellen, wie KI-Systeme Intelligenz mit Handlung verknüpfen. GPT Image 2 führte eine Reasoning-Schleife vor der Pixelerzeugung ein. Codex wurde zu einem vollständigen Desktop-Agenten auf OS-Ebene, der den menschlichen Referenzwert auf Computer-Use-Benchmarks übertraf. GPT-5.5 definierte die Frontier-Leistungsmetrik neu: nicht mehr rohe Benchmark-Scores, sondern ausgelieferte Intelligenz pro Output-Token. Claude Design renderte Reasoning unmittelbar als bearbeitbares HTML — und umging damit die Pixel-Primitive vollständig.
Die architektonische Gemeinsamkeit aller vier Releases ist präzise: Der Reasoning-Stack verlagerte sich stromaufwärts der Ausführungsprimitive. Zuvor war die Beziehung zwischen einem LLM und einem nachgelagerten System (Bildsynthese, Browser, Betriebssystem, Code-Interpreter) konnektiver Natur — ein Reasoning-Modell erzeugte ein Artefakt, das eine separate Ausführungsschicht konsumierte. Diese April-Releases machten diese Beziehung integrativ: Reasoning koordiniert, sucht, verifiziert und iteriert jetzt, bevor es sich auf das Ausgabe-Artefakt festlegt. Die Ausführungsprimitive wird zum Renderformat einer abgeschlossenen Reasoning-Spur.
Zwei Metriken signalisieren diesen Generationswechsel deutlicher als Benchmark-Tabellen. Die erste ist Intelligence-per-Token: GPT-5.5 erzielt einen Terminal-Bench-Score von 39,1 bei 2.165 Output-Tokens, gegenüber GPT-5.4s 34,2 bei 4.950 Tokens — eine 2,5-fache Verbesserung der ausgelieferten Intelligenz pro Token bei gleichzeitig höherer absoluter Leistung, obwohl sich der Preis pro Token verdoppelt hat. Die zweite ist das Überschreiten des menschlichen OS-World-Baselines: Codexs 78,7 % gegenüber dem menschlichen Basiswert von 72,4 % ist die erste Bestätigung von einem allgemeinen Modell, dass agentischer Computer-Use das menschliche Leistungsniveau bei realen Desktop-Aufgaben übertroffen hat.
Die nachgelagerten Konsequenzen für Praktiker und Plattformbetreiber sind struktureller Natur und verstärken sich bereits. Spezifikationsqualität — Briefing-Verfassen, Constraint-Dokumentation, kompositorische Absicht — ist zur bindenden Hebelgröße geworden. Der agentengesteuerte Konsum von Ausführungsprimitiven beginnt den menschlichen Konsum zu übersteigen, mit einer Ökonomie, die Skalierung gegenüber der Session-Erfahrung begünstigt. Und die Middleware-SaaS-Schicht, die auf Basis menschlicher Interaktion bepreist wird, steht einer Kompression von beiden Seiten gegenüber.
What's Shifting
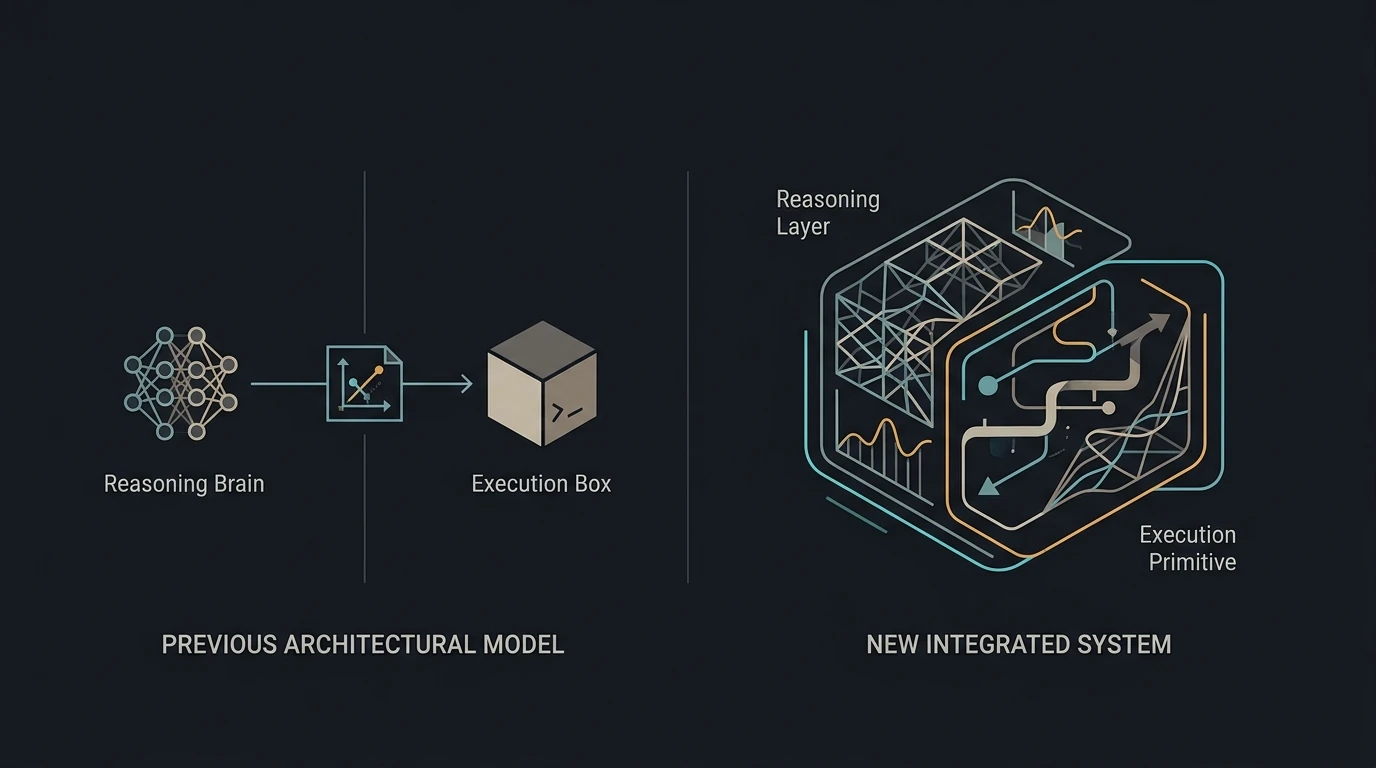
Der KI-Produktstack vor 2026 hatte eine konsistente architektonische Eigenschaft: Reasoning und Ausführung waren benachbarte Systeme, die über Artefakte kommunizierten. Ein LLM erzeugte einen Text-Prompt, den ein Diffusionsmodell renderte. Ein LLM generierte JavaScript, das ein Browser unabhängig ausführte. Ein Reasoning-Modell verfasste Copy, die menschliche Designer von Hand layouteten. Das LLM koordinierte die Arbeit; die Ausführungsprimitive blieben separate Substrate.
Die April-2026-Releases lösten diese Trennung an vier Stellen gleichzeitig auf — und der Mechanismus ist in jedem Fall identisch.
GPT Image 2s Thinking-Modus verbringt 10–20 Sekunden damit, Komposition, Typografiehierarchie, Objektplatzierung und Constraint-Erfüllung zu durchdenken, bevor es sich auf einen Pixel festlegt. Die Web-Suche läuft innerhalb der Generierungsschleife selbst: Das Modell kann ein geologisch korrektes Tiefendiagramm der Straße von Hormuz im Stil von Richard Scarrys Illustrationen rendern, indem es während der Generierung Live-Geodaten abruft und diese in einem einzigen Durchlauf mit einer ästhetischen Übersetzung fusioniert, wie in der Analyseberichterstattung vom 25. April demonstriert (Nate B Jones, YouTube). Ein Selbstverifizierungsdurchlauf liest die Ausgabe erneut gegen den Prompt, bevor sie zurückgegeben wird — sichtbar daran, wie Tippfehler sich zwischen dem ersten und zweiten Generierungsdurchlauf innerhalb einer einzigen Anfrage selbst korrigieren. Das Ausgabebild ist nicht nur Pixel; es ist eine komprimierte Spur eines Suchen-Planen-Rendern-Verifizieren-Zyklus, der als Bild gerendert wird.
Codex wendete dasselbe architektonische Muster auf den Computer-Use auf OS-Ebene an. Hintergrundagenten des Desktop-Releases vom 16. April kapern weder den Cursor-Fokus noch unterbrechen sie das aktive Fenster; sie laufen parallel über die gesamte Mac-Anwendungsoberfläche, während der Nutzer mit anderen Aufgaben fortfährt. Das Modell versteht seinen eigenen Bildschirmzustand gut genug, um visuelle Regressionen autonom zu erkennen, Bug-Reproduktionen über Screenshot-to-PR zu erstellen und tägliche Commits sowie Kalendereinträge in Notion-Meetingprotokolle zu kompilieren. OpenAIs Übernahme von Software Applications Inc. im Oktober 2025 — dem Sky-Team, dessen Linie von Workflow zu Apple Shortcuts reicht und dessen Mitglieder kumulative Jahrzehnte bei Apple mit OS-level-Integrationen verbrachten — diente gezielt dazu, diese Art von Nicht-Modell-Expertise zu akquirieren (Nate B Jones, YouTube). Anthropic tätigte Anfang 2026 eine parallele Übernahme (Recept) für die Windows-Desktop-Kontrolle. Beide Labs kamen gleichzeitig zu dem Schluss, dass reasoning-fähige Modelle OS-level-Körper benötigen, nicht nur API-Oberflächen.
Claude Design, vier Tage vor GPT Image 2 veröffentlicht, erreichte dasselbe architektonische Ziel durch eine andere Primitive-Wahl. Anstatt Reasoning stromaufwärts der Pixel zu verlagern, entfernte Anthropic die Pixel-Schicht vollständig: Die Ausgabe ist bearbeitbares HTML, das direkt an Claude Code für die Produktion übergeben werden kann. Nate B Jones' Analyse rahmt beide Launches als nachgelagert zur selben grundlegenden Erkenntnis: Reasoning hat sich dem visuellen Stack angeschlossen, und Erstversionen visueller Arbeit sind nun etwas, das ein Reasoning-Modell aus Long-Form-Kontext ausführen kann. Für gerenderte Assets — Poster, Menüs, Produktfotografie, Social-Media-Bilder — ist GPT Image 2 die geeignete Ausgabe-Primitive. Für funktionierende Prototypen — Landing Pages, Dashboards, interaktive Mock-ups — ist Claude Designs HTML-Ausgabe bereits produktionsreif. Eine langfristige Konvergenz beider Zweige ist wahrscheinlich.
GPT-5.5s Token-Effizienz-Story vervollständigt das Bild. Sam Altmans Launch-Thread-Formulierung — „in erheblichem Maße müssen wir jetzt ein AI-Inference-Unternehmen werden" — benennt die Verschiebung präzise: Die Wettbewerbsachse hat sich von der Benchmark-Obergrenze zur ausgelieferten Intelligenz pro Dollar auf Aufgabenebene verschoben (Sam Altman, X/Twitter). swyx, am Tag des GPT-5.5-Launches schreibend, brachte es direkt auf den Punkt: „Der am meisten unterschätzte Teil des heutigen OpenAI-Launches ist die Codex-App-Transformation, nicht GPT-5.5" — in der Erkenntnis, dass die eigentliche Produktgeschichte die Plattformreichweite war, nicht die Modellleistung per se (swyx, X/Twitter).
Evidence
Die 26-Punkte-Arena-Lücke, die GPT Image 2 gegenüber Google Nano Banana 2 erzielte (93 % vs. 67 %), ist das eindeutigste Signal dafür, dass ein Sprung stattgefunden hat. Bildgenerierungs-Leaderboards trennen sich historisch um drei bis vier Punkte; Platzhirsche tauschen die Plätze innerhalb eines engen Bandes, während inkrementelle Verbesserungen sich anhäufen. Eine 26-Punkte-Lücke impliziert architektonische Divergenz, nicht Optimierungs-Tuning. Nate B Jones' fünfteilige Strukturanalyse (YouTube) führt die Lücke auf vier spezifische Mechanismen zurück, die im Zusammenspiel wirken: den Reasoning-Vorpass, die Web-Suche innerhalb der Generierungsschleife, acht kohärente Frames mit Charakterkontinuität aus einem einzigen Prompt und den Selbstverifizierungspass. Frühere Bildgeneratoren waren direkte Sampler; GPT Image 2 ist eine Plan-und-Ausführungs-Schleife, die als Bild rendert.
Reale Produktionsdemonstrationen bestätigen den Benchmark. Takuya Matsuyama, Entwickler der Inkdrop-Notiz-App, fütterte GPT Image 2 mit App-Dokumentation, V6-Release-Notes und Essays, die er über japanische Ästhetik geschrieben hatte, und erhielt als Rückgabe einen vollständigen Landing-Page-Mock-up — eine Hokusai-inspirierte Hero-Illustration, Wabi-Sabi-Philosophie-Sectioncards, ein Feature-Grid und Typografie, die die Sprache und ästhetische Philosophie seines schriftlichen Materials widerspiegelten — aus einem einzigen Prompt. Microsoft Foundrys Zava-Blumenlieferungs-Demo stellte eine vollständige Werbekampagne innerhalb eines leeren U-Bahn-Waggon-Fotos in drei Prompts zusammen, von Anfang bis Ende. Das sind Praktiker, die Produktionsaufgaben lösen, keine kuratierten Fähigkeitsdemonstrationen.
Die Codex-Evidenz hat eine andere Form. Der 78,7-%-OS-World-Score gegenüber einem menschlichen Basiswert von 72,4 % ist als Schwellensignal von Bedeutung: GPT-5.5 ist das erste Allzweckmodell mit nativem Computer-Use, das die menschliche Leistung bei der Erledigung realer Desktop-Aufgaben nachweislich übertrifft — nicht nur auf engen Benchmarks (Developers Digest, YouTube). Die von frühen Testern berichteten Produktions-Workflows bestätigen den Benchmark: Forscher gaben GPT-5.5 nur eine übergeordnete algorithmische Idee und erhielten am nächsten Morgen abgeschlossene Experiment-Sweeps mit Dashboards und Ergebnissen — ohne dass ein Mensch Code oder Terminal berührt hatte. Ein OpenAI-Manager schrieb öffentlich: „Ich kann jetzt CUDA-Kernel wie ein Profi schreiben. Ich kann mich darauf verlassen, dass es meine Forschungsexperimente ausführt."
GPT-5.5s Terminal-Bench-Zahlen liefern die sauberste Quantifizierung der Intelligence-per-Token-Verschiebung. GPT-5.4 erzielte 34,2 bei durchschnittlich 4.950 Output-Tokens. GPT-5.5 erzielte 39,1 bei 2.165 Output-Tokens — sowohl höherer absoluter Score als auch 56 % weniger Tokens, was eine 2,5-fache Verbesserung im Intelligence-per-Token-Verhältnis ergibt, bevor die Preisgestaltung in die Berechnung einfließt (Matthew Berman, YouTube). Der Preis verdoppelte sich auf 5 $/M Input und 30 $/M Output, aber die effektiven Kosten pro Aufgabe sind bei den meisten Workloads niedriger, da die Token-Reduktion die Preiserhöhung übersteigt. Der Enterprise-Box-Benchmark zeigte bedeutende Gewinne in Finanzdienstleistungen (+20 Punkte), Gesundheitswesen (+17 Punkte) und öffentlichem Sektor (+13 Punkte) bei der Bewältigung komplexer Arbeitsaufgaben.
DeepSeek V4s gleichzeitige Veröffentlichung bestätigt, dass die Intelligence-per-Token-Effizienzkurve plattformübergreifend und nicht OpenAI-spezifisch ist. Durch den Einsatz von hybridem Compressed Sparse Attention (CSA) und Heavy Compressed Attention (HCA) — die KV-Token im Verhältnis 4:1 bzw. 128:1 komprimieren — erzielt V4 einen 1M-Token-Kontext, während es 27 % der FLOPs von V3.2 und 10 % des KV-Cache von V3.2 bei gleicher Fenstergröße verbraucht. V4 Pros Preisgestaltung von 1,74 $/M Input-Tokens, mit Cache-Hit-Preisen von 0,14 $/M, macht es auf den meisten Benchmarks bei rund 35 % der Kosten materiell wettbewerbsfähig mit GPT-5.5. Zwei unabhängige Labs, zwei unabhängige Architekturen, die innerhalb derselben Woche in dieselbe Effizienzrichtung konvergieren.
Countertrends

Die im selben Zeitfenster geäußerten architektonischen Einwände sind substanziell und verdienen eine direkte Auseinandersetzung statt Dismissal.
Yann LeCun postete am Tag des GPT-5.5-Launches, dass der Aufbau von Systemen mit echter Intelligenz „gesunden Menschenverstand, die Fähigkeit, die Konsequenzen des eigenen Handelns vorherzusagen, die Fähigkeit zu planen, die Fähigkeit zu schlussfolgern" erfordere — und dass generative Architekturen diese Fähigkeiten nicht bereitstellen können. Die am 24. April veröffentlichte LeWorldModel (LeWM)-Forschung gibt seiner Position empirisches Fundament: Ein JEPA-basiertes Weltmodell, das aus rohen Pixeln trainiert wurde, erzielt eine 96-prozentige Planungserfolgsrate bei 0,98 Sekunden gegenüber 78 % bei 47 Sekunden beim vorherigen besten Ansatz und internalisiert echte physikalische Constraints (Objekte können nicht teleportieren; Licht fällt aus Quellen, nicht gleichmäßig). LeWM erfordert eine nicht-generative Architektur — Joint Embedding Predictive Architecture statt Next-Token-Prediction — und operiert derzeit bei 15 Millionen Parametern in Spielzeugumgebungen, nicht im Produktionsmaßstab. Die Reasoning-Stack-Expansion in diesem Report betrifft Wissensarbeit und kreative Arbeit. LeCun weist auf eine distinkte Schicht hin: Robotik, physische Automatisierung und Systeme, die kausale Konsequenzen modellieren müssen. Beide Beobachtungen können gleichzeitig korrekt sein.
Gary Marcus verstärkte ein paralleles Argument: Informationstechnologie hat die Architektur des täglichen Lebens — Heizung, Transport, Ernährung, Bauwesen — seit 1970 nicht materiell verändert. Die atombasierten Technologien, die die Kurve tatsächlich bewegten, sind Kupferdraht, Beton, Penicillin und der Verbrennungsmotor. Code kann kein Haus isolieren; kein Algorithmus hat je eine Wasserleitung verlegt. Diese Rahmung ist auf der zivilisatorischen Ebene korrekt, beantwortet aber eine andere Frage als die, auf die GPT Image 2 und Codex eine Antwort liefern. Die Produkte in diesem Report operieren in der Wissens- und Kreativarbeit, wo die Disruptions-Kurve bereits steil ist und der wirtschaftliche Einfluss kurzfristig messbar ist.
Das LLM-Trugschluss-Papier, von AlphaSignal am 23. April aufgegriffen, stellt einen operativ unmittelbaren Gegentrend vor: Wenn KI-Ausgaben flüssig sind, rechnen Nutzer sie sich unbewusst an, was das Selbstvertrauen aufbläst, während echte Kompetenz still erodiert. Das Papier dokumentiert das Muster in vier Bereichen — Programmieren, Schreiben, Analyse und Spracherwerb — und rahmt es als „den GPS-Effekt auf die gesamte Karriere angewendet". Dies ist präzise deshalb ernst zu nehmen, weil es die Kehrseite des Spezifikations-Skill-Arguments ist: Dieselbe Verschiebung, die Briefing-Qualität als die bindende Constraint erhebt, schafft auch einen Failure Mode, bei dem Praktiker Prompt-Flüssigkeit mit echter Kompetenzentwicklung verwechseln. Organisationen, die KI-Augmentations-Workflows aufbauen, benötigen explizite Mechanismen zur Erhaltung von Praktiker-Skill-Dichte — nicht nur von Output-Geschwindigkeit.
Kostendisziplin ist je nach Workload-Typ uneinheitlich. GPT-5.5 bei 13 Cent pro Seite auf ParseBench OCR im mittleren Thinking-Modus ist fünfmal teurer als LlamaParse bei 1,25 Cent pro Seite. Das Intelligence-per-Token-Argument überträgt sich auf Aufgaben, die Reasoning-Komplexität erfordern; es schließt die Kosten-Nutzen-Lücke nicht einheitlich für Commodity-Workloads, bei denen einfachere, billigere Tools bereits ausreichende Genauigkeit liefern. Aufgabenspezifität ist erforderlich, bevor Effizienzaussagen von Benchmark-Tabellen auf Betriebsbudgets übertragen werden.
Persönliche KI-Desillusionierung, offen von Kitze auf der AI Engineer Europe-Konferenz am 23. April dokumentiert, ist ein Frühindikator für Zuverlässigkeitslücken, die unterhalb der Modell-Fähigkeits-Schicht fortbestehen. Die OpenClaw-Adoption der Tinkerer-Klasse hat Wände nicht in der Modellintelligenz getroffen, sondern in der Zuverlässigkeit der Multi-Agenten-Orchestrierung, der Eignung der UI-Oberfläche (Discord und Telegram wurden nicht für das Agenten-Management gebaut) und der Reibung beim Dateneintrag für das Life-OS. Ethan Mollick hob dieselbe Lücke aus einem Forschungswinkel hervor: „Organisationsdesign für Agenten UND Benchmarking von Multi-Agenten-Systemen sind die nächste kritische Frontier für wirtschaftlichen KI-Impact — wir wissen darüber wirklich sehr wenig." Reasoning stromaufwärts der Primitive zu verlagern ist notwendig, aber nicht hinreichend; die Koordinierungsschicht zwischen mehreren Reasoning-upstream-Agenten bleibt ein offenes Problem.
Forecast
Die Primitive-Expansion wird auf einem vorhersehbaren Trajekt fortgesetzt. Reasoning ist nun strukturell stromaufwärts von Pixel (GPT Image 2), bearbeitbarem Code (Claude Design), OS-level-Aktionen (Codex) und allgemeiner Inferenz (GPT-5.5). Audio, Video, 3D-Mesh und Sensordaten-Primitive stehen als nächstes in der Integrationssequenz. Veo und aufkommende Spatial-Computing-Frameworks befinden sich auf demselben Weg: Reasoning wird ihre Outputs koordinieren, bevor ein einziger Frame in den Speicher übertragen wird. Die vier April-2026-Produkte sind keine Endpunkte; sie sind die ersten bestätigten Instanzen eines strukturellen Musters, das sich innerhalb von 18 bis 24 Monaten auf alle digitalen Ausführungsoberflächen ausweiten wird.
Das Wachstum der Spezifikationsschicht ist strukturell und dauerhaft. Wenn Reasoning stromaufwärts der Ausführung wandert, wandert der Praktikerhebel mit. Das Briefing, das Constraint-Dokument, die Marken-Systemreferenz, das Memo zur kompositorischen Absicht — das sind die Differenzierungsfaktoren, wenn Erstversions-Ausführung automatisiert ist. Dies ist dieselbe berufliche Migration, die Textverarbeitungsprogramme Schriftsetzern und Webbrowser Verlagen aufzwangen: Die Schicht, die menschliches Urteilsvermögen erfordert, wandert stromaufwärts, während die mechanische Ausführungsschicht komprimiert. Die voraus positionierten Praktiker sind jene, die bereits in expliziten Constraints, Referenz-Assets, Typografieregeln und kompositorischer Absicht denken. Diejenigen, deren Wert in der Ausführungskunst lag, stehen Migrationsdruck gegenüber, nicht Eliminierung.
Der agentengesteuerte Konsum wird den menschlich gesteuerten Konsum schneller überschreiten, als aktuelle Produkt-Roadmaps anerkennen. Der sichtbare Markt für Bildgenerierung ist menschlich getriebene Designarbeit; das ist es, was Produktmarketing adressiert. Der unsichtbare Markt — Agenten-Harnesses (Conway, Hermes, Codex-Workflows), die Bildgenerierung als computationale Unterroutine innerhalb automatisierter Pipelines aufrufen — wird schneller skalieren, weil seine Ökonomie strukturell anders ist: Die Latenztoleranz ist höher, der Preis pro Bild ist wichtiger als die Session-UX, und viele generierte Artefakte werden nie von einem Menschen gesehen, sondern fließen direkt in den nächsten agentischen Schritt. Middleware-SaaS-Anbieter, die gegen eine große Oberfläche menschlicher Interaktion bepreisen, sind einer Kompression von beiden Seiten ausgesetzt: von der Plattformschicht (OpenAI und Anthropic bieten native Fähigkeiten an) und von der Agentenschicht (Automatisierung, die die menschliche Engagement-Annahme eliminiert).
Token-Effizienz wird zur primären Wettbewerbsachse, da sich die Frontier-Leistungslücke verengt. DeepSeek V4 Flash bei 0,14 $/M Input und GPT-5.5 bei 5 $/M demonstrieren, dass die Preis-zu-Intelligenz-Bandbreite über glaubwürdige Frontier-Optionen nun mehr als das 30-Fache umfasst. Multi-Modell-Routing — der Einsatz verschiedener Modelle für verschiedene Aufgaben-Tiers basierend auf Intelligence-per-Dollar — wird bereits von erfahrenen Teams praktiziert und wird zur Basisinfrastruktur werden, wenn sich die Kosten-Leistungs-Kurve über Anbieter hinweg fragmentiert. Die Frage „Welches Modell ist am klügsten?" wird zunehmend durch „Welches Modell liefert bei diesem spezifischen Aufgaben-Tier ausreichende Intelligenz pro Dollar?" verdrängt werden.
Die Trust-Stack-Sanierungslücke ist die folgenreichste Open-Problem-Chance, die dieses Zeitfenster aufgezeigt hat. GPT Image 2 mit 99 % In-Image-Text-Genauigkeit, mit Web-Wissen vom Dezember 2025 und Live-Suchfähigkeit, erzielte über 70 % „echtes Foto"-Durchgangsraten in blinden Arena-Tests über gefälschte Kassenbelege, Slack-Screenshots, Bordkarten, Apotheketiketten und behördliche Hinweise. Content Credentials überleben einen Screenshot-Zuschnitt nicht — das war nie der Fall. Journalistische Fact-Check-Infrastruktur, KYC-Anbieter, Versicherungsbetrugs-Erkennung, Zollbehörden und Rechtsauffindungs-Workflows operieren alle auf Evidenz-Vertrauensannahmen, die nicht mehr gelten. Die Bild-Verifizierungsschicht hat keinen adäquaten Anbieter, und der Bedarf wird durch 2026 und darüber hinaus erhebliche institutionelle und kommerzielle Investitionen generieren. Das Unternehmen, das zuverlässige Chain-of-Custody-Verifizierung für visuellen Beweis in der Post-GPT-Image-2-Ära aufbaut, stellt eine der am klarsten definierten Produktchancen des aktuellen Zyklus dar.


