
Zusammenfassung
Cloud-KI-Abonnements stehen unter strukturellem Druck, der nicht mehr zu übersehen ist. Innerhalb eines 48-Stunden-Fensters Ende April 2026 konvergierten sechs unabhängige Signalquellen auf dieselbe Schlussfolgerung: Die Ökonomie des Verkaufs unbegrenzter Cloud-KI-Inferenz im Flatrate-Abonnement ist defekt. Ein viraler Abrechnungsfehler in Claude Code, GitHub Copilot Pro mit degradiertem Leistungsumfang, Anthropics dokumentierte Drosselungsereignisse zu Stoßzeiten, eine Finanzanalyse, die OpenAIs Verluste für 2026 auf rund 14 Milliarden Dollar beziffert, reale Benchmarks, die zeigen, dass Open-Source-Modelle bei 63–76 % niedrigeren Kosten als geschlossene Frontier-Modelle laufen, und eine zweistündige Masterclass, die fast vollständig um Techniken zur Kontingentschonung strukturiert ist – nichts davon sind isolierte Vorfälle. Sie sind Symptome derselben grundlegenden Arithmetik.
Der Bruch ist kein diskreter Moment, sondern eine beschleunigende Richtung. KI-Labs bewegen sich – zunächst vorsichtig, dann schneller – in Richtung tokenbasierter Abrechnung, produktflächen-separierter Kontingentgrenzen und Anti-Missbrauchsheuristiken, die häufig unbeabsichtigte Abrechnungskonsequenzen erzeugen. Unternehmen reagieren mit Budgetmodellen, die Token-Kosten als unbegrenzte Varianz behandeln – was die Beschaffung von Cloud-KI auf CFO-Ebene schwer genehmigungsfähig macht. Der daraus resultierende Druck zwingt gleichzeitig zur Änderung der Preisstruktur bei den großen Labs und beschleunigt die Reifung lokaler und Open-Source-Alternativen über ihre historische Qualitätsobergrenze hinaus.
Für jede Organisation, die KI-Workloads in großem Maßstab betreibt, ist die praktische Implikation unmittelbar: Modell-Routing-Strategien – nicht Anbieterloyalität – sind das richtige Beschaffungsrahmenwerk für die aktuelle Periode. Der Markt sortiert sich schneller, als die meisten Anbieter-Roadmaps einräumen.
Was sich verschiebt

Die grundlegende Verschiebung geht von „unbegrenztem Zugang zu einem Modell gegen eine monatliche Flatrate" zu „einem definierten Compute-Budget, tokenbasiert abgerechnet, mit harten Obergrenzen pro Produktfläche". Das ist kein neues Konzept in der Cloud-Infrastruktur – API-basierte Nutzungsabrechnung ist seit Mitte der 2000er-Jahre die Norm im Cloud-Compute. Was neu ist, ist das Tempo, mit dem KI-Labs in diese Richtung gehen, obwohl sie einer ganzen Nutzergeneration die gegenteilige Prämisse verkauft haben: unbegrenzter, reibungsloser KI-Zugang für einen vorhersehbaren monatlichen Preis.
Die Chronologie der Verschlechterung ist spezifisch und komprimiert sich. GitHub Copilot Pro entfernte den Zugang zur Opus-Modellklasse von Anthropic, kürzte Nutzungslimits und stoppte die Aufnahme neuer Abonnenten – alles innerhalb desselben Quartals 2026. Anthropic reduzierte die Claude-Pro-Code-Limits während der US-Stoßzeiten rund um den 22.–26. April 2026, eine Änderung, die sein Head of Growth zunächst als „Experiment" charakterisierte, bevor er unter Nutzerdruck zurückruderte. Claude Design, am 17. April 2026 gestartet, trägt ein eigenes wöchentliches Compute-Kontingent, das vollständig von Claude- oder Claude-Code-Budgets getrennt ist – ein Nutzer, der $200/Monat für den Max-20x-Plan zahlt, navigiert nun drei separate Ressourcenpools unter demselben Konto. Nate Herks öffentliche Masterclass zu Claude Design stellte fest, dass das Erstellen einer vollständigen Markenidentität (Pitch Deck, Landing Page, Mobile-App-Prototyp und animiertes Launch-Video) rund 95 % des wöchentlichen Claude-Design-Kontingents verbrauchte – sodass das Demonstrationsvideo fast vollständig um Techniken zur Compute-Rationierung statt zur freien Produktnutzung strukturiert wurde (Nate Herk, YouTube).
Das strukturelle Argument hinter diesen Entscheidungen ist nicht schwer zu finden. Mandar Karhades vielgelesene Analyse auf GoPubby schätzt, dass OpenAI in 2025 rund 9 Milliarden Dollar bei 13 Milliarden Dollar Umsatz verbrannte, wobei die Inferenzkosten gegenüber Microsoft allein bis November 2025 auf 12 Milliarden Dollar anstiegen. Projizierte Verluste für 2026 liegen bei rund 14 Milliarden Dollar. Anthropics Bruttomarge, so dieselbe Analyse, hat sich von einem Zielwert von 50 % auf rund 40 % komprimiert. Die zentrale These: „Günstige Inferenz" ist keine Produktentscheidung. Sie ist eine VC- und Hyperscaler-Quersubventionierung – gleichzeitig finanziert von denselben Unternehmen, die diese Labs beliefern, aufbauen und von ihnen kaufen – und ist einen wesentlichen Liquiditätsereignis von einer ungeordneten Neubepreisung entfernt (GoPubby / AI Advances).
Belege
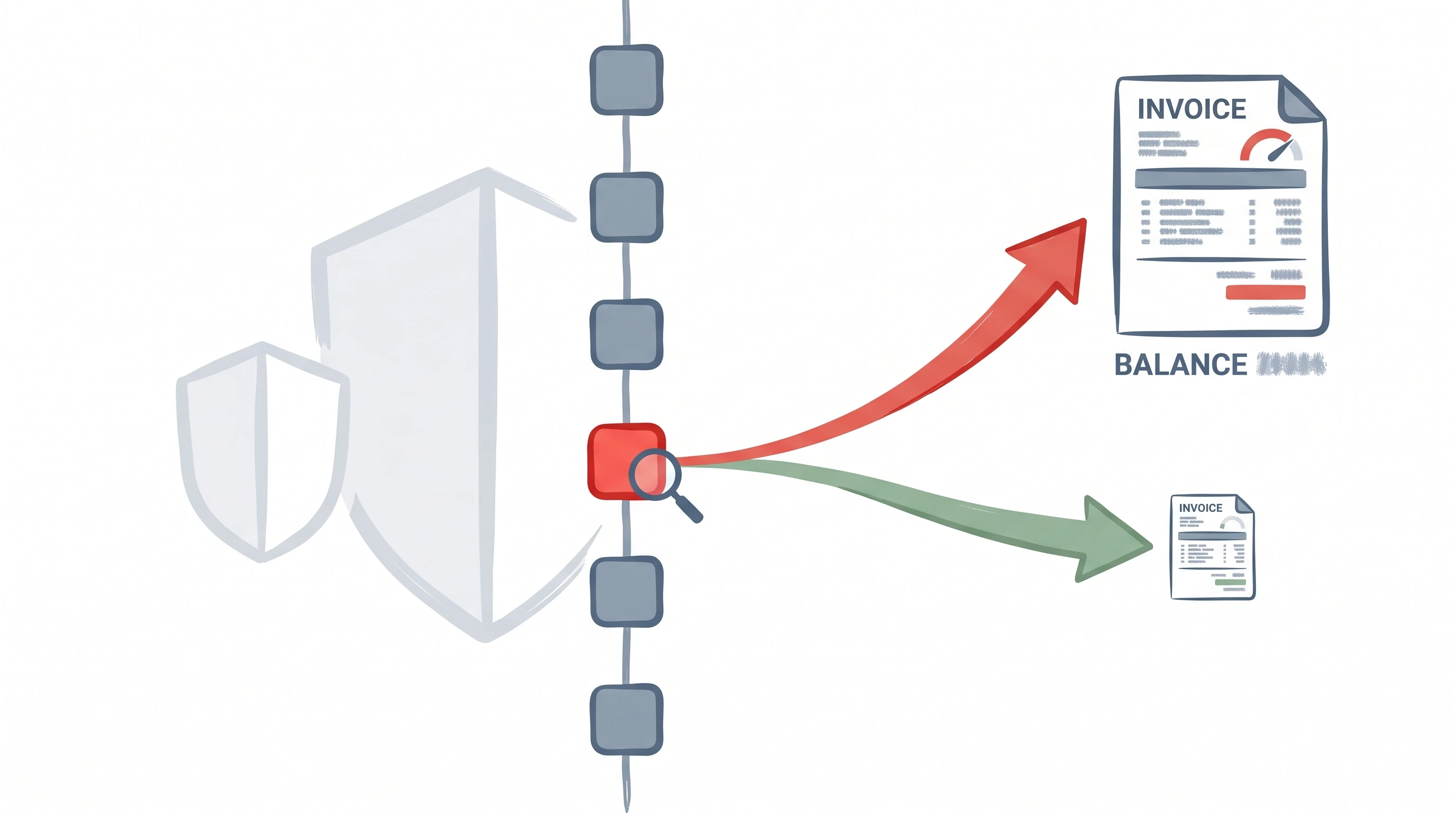
Der schärfste Datenpunkt in diesem Cluster ist der Claude-Code-Abrechnungsfehler, der in einem GitHub-Issue dokumentiert und von Tim Carambat am 29. April 2026 amplifiziert wurde. Claude Codes Anti-Missbrauchssystem verwendete einen Regex-Abgleich über die Git-Repository-History eines Nutzers, um das Vorhandensein konkurrierender Coding-Harnesses zu erkennen – spezifisch den Dateinamen Hermes.MD (Großbuchstaben, .MD-Erweiterung). Nutzer des teuersten Max-20x-Plans von Anthropic, die diesen String irgendwo in der Git-History ihres Projekts hatten, wurden stumm in „Extra-Nutzungs"-Abrechnungsstufen umgeleitet, unabhängig von ihrem tatsächlichen Token-Verbrauch. Die betroffenen Nutzer lagen dabei deutlich unterhalb der definierten Nutzungsgrenze ihres Plans.
Die technischen Details sind aufschlussreich. Der Auslöser war groß-/kleinschreibungsempfindlich und erweiterungsspezifisch: Kleinbuchstaben hermes.md aktivierten ihn nicht, .txt-Varianten ebenso wenig, noch das Wort hermes ohne die Großbuchstaben-Erweiterung. Nur das großgeschriebene Hermes.MD-Muster – das exakte Dateinamenformat von Hermes Agent, einem Open-Source-Alternativ-Harness von Nous Research – leitete Nutzer in Mehrnutzungs-Abrechnung um. Das ist kein ausgeklügelter Laufzeit-Inferenz-Monitor. Es ist ein String-Abgleich zum Abrechnungszeitpunkt, angewendet auf historische Einträge, die der Nutzer möglicherweise nicht bewusst in seiner Git-History behalten hat (Tim Carambat, YouTube).
Boris Cherny, der ursprüngliche Autor von Claude Code, bestätigte das Problem im GitHub-Bug-Report als „ein überaktives Anti-Missbrauchssystem" – eine Formulierung, die als technische Bestätigung des Mechanismus fungiert. Was folgte, legte ein zweites, eigenständiges Governance-Problem offen: Anthropics Head of Growth versprach öffentlich Rückerstattungen und einen Monat kostenloser Credits über einen persönlichen Twitter-Account, während Kommentare im selben GitHub-Issue gleichzeitig Erstattungen ablehnten. Carambats Charakterisierung war pointiert: Die Kommunikation wichtiger Produktrichtlinienentscheidungen über persönliche Social-Media-Accounts einzelner Mitarbeiter signalisiert organisatorische Unreife genau in dem Moment, in dem Nutzer institutionelle Klarheit benötigen. Der Widerspruch zwischen dem öffentlichen Versprechen und der Support-Queue-Antwort wurde nie formal aufgelöst.
Der Mechanismus offenbart die zugrundeliegende Ökonomie. Anthropic kann in Echtzeit nicht zuverlässig unterscheiden zwischen einem Nutzer, der Claude Code mit hohem Inferenzvolumen betreibt, und einem Nutzer, der ein konkurrierendes Harness gegen ein anderes Modell mit inaktivem API-Schlüssel nutzt. Der Regex-über-Git-History-Workaround ist die Art von Heuristik, die ein Team baut, wenn das eigentliche Problem – Kostenüberwachung nahe einer Preisuntergrenze – nicht sauber lösbar ist. Carambats Lesart ist explizit: Der Preis von $200/Monat für den Max-20x-Tarif deckt die tatsächlichen Compute-Kosten bei aktuellen Nutzungsmustern nicht, und Anthropic improvisiert Antworten auf das daraus resultierende Defizit (Tim Carambat, YouTube).
Dieselbe Dynamik zeigt sich in unabhängigen Verfügbarkeitsdaten. Nate B. Jones' Benchmark-Arbeit ergab, dass Anthropics 90-Tage-Reliability-Seiten eine Verfügbarkeit von rund „einer Neun" – ca. 98 % – für mehrere Dienste zeigen, unterhalb des Drei-Neunen-Standards, den OpenAI näher aufrechterhalten konnte. Jones vermerkte, dass Anthropic in den vorangegangenen 30 Tagen Kapazitätsverträge über mehr als 10 Gigawatt Compute abgeschlossen hatte, weil die Claude-Nachfrage das Angebot übertraf. Peak-Hour-Drosselung ist keine diskrete Produktentscheidung; sie ist ein Symptom dafür, dass die Infrastrukturkapazität der Adoption in einem Tempo hinterherläuft, das die aktuelle Preisstruktur nicht finanzieren kann (Nate B Jones, YouTube).
Reale Kosten-Benchmarks aus LangChains Fleet-Agent-Tests lieferten den Marktkontext. Bei der Ausführung gleichwertiger agentischer Aufgaben über mehrere Modelle dokumentierte LangChain: Claude Sonnet 4.6 bei $0,19 pro Lauf; GLM 5.1 über FireworksAI bei $0,07 (63 % günstiger); Kimi K2.6 bei $0,05 (74 % günstiger); und bemerkenswerterweise Anthropics eigenes Opus 4.7 bei $0,045 pro Lauf über die API statt über eine Abonnement-Stufe – 76 % günstiger als Sonnet 4.6 auf Pro-Lauf-Basis. LangChain-CEO Harrison Chase nannte Closed-Model-Kosten als „das große Thema 2026" und listete Open-Source-Modell-Optimierung als explizite strategische Roadmap-Priorität (X / @hwchase17). Die Kostendifferenz ist nicht marginal. Im großen Maßstab ist sie der Unterschied zwischen einem KI-Workload, der in ein Abteilungsbudget passt, und einem, der es nicht tut.
Gegentrends
Das lokale und Open-Source-KI-Ökosystem ist schneller gereift, als die meisten Analysten geschlossener Labs öffentlich eingeräumt haben. Carambats direkter Vergleich ist aufschlussreich: Als er erstmals Code zu AnythingLLM beitrug, war das verfügbare lokale Modell Llama 2 mit einem 4.000-Token-Kontextfenster – ein Modell, das er ohne Ironie als „einen Witz" bezeichnet. Heute läuft Qwen 3.5 0.8B mit einem 128.000-Token-Kontextfenster auf Consumer-Hardware und liefert Ergebnisse, die mit frühen Mid-Tier-Kommerziellen Modellen konkurrieren. Forschung zu 1-Bit-Gewichtsquantisierung (BitNet) und TurboQuant treibt die Inferenzeffizienz entlang derselben Trajektorie weiter.
Die Open-Source-Modellkostenkonvergenz beschleunigt sich gleichzeitig auf Modellebene. DeepSeek v4, Ende April 2026 veröffentlicht – von Analyst swyx als Lieferung „der besten offenen Basismodelle" mit neuartigen Langkontext-Effizienztechniken wie Compressed Sparse Attention, Hybrid Cross-Attention und gemischter Schlüssel-Wert-Präzision eingestuft – erschien ohne den Benchmark-Fokus, der für Modellveröffentlichungen typisch ist, was darauf hindeutet, dass das Team gegen eine Qualitätslatte statt gegen eine Leistungsrangliste geliefert hat. Kimi K2.6, unter einer modifizierten MIT-Lizenz veröffentlicht, zeigte in LangChains Tests wettbewerbsfähige agentische Leistung bei $0,05 pro Lauf. Der Abstand zwischen den besten Open-Weight-Modellen und geschlossenen Frontier-Modellen verengt sich schneller als die Benchmark-Schlagzeilen vermuten lassen.
Nicht jedes Signal deutet auf eine Dominanz lokaler KI hin. Die Unternehmensreaktion auf Cloud-Kostenunsicherheit ist zweigeteilt statt einheitlich. Technische Teams – insbesondere jene, die bereits agentische Workflows betreiben – bauen aktiv Modell-Routing-Strategien auf und behalten Claude Code oder GPT-5.5 für hochwertige, hochkomplexe Aufgaben bei, während sie Routine-Agentenarbeit zu lokalen oder Open-Source-Modellen routen, wo die Token-Kosten faktisch null sind. Nicht-technische Unternehmenseinkäufer bleiben größtenteils in von IT-Beschaffung verwalteten Per-Seat-Kaufzyklen gefangen. Ihre Migration zur tokenbasierten Abrechnung ist unfreiwillig und kommt häufig als unbudgetierte Rechnung an – was CFO-seitigem Widerstand gegen KI-Tool-Genehmigungen erzeugt, den die Labs noch nicht mit kohärenter Preiskommunikation adressiert haben.
Der Harness-Markt selbst hat sich über das hinaus diversifiziert, was die meisten Kommentare einräumen. Mehrere Coding-Harnesses – pi.dev, Hermes Agent von Nous Research und Codex – sind nun legitime Claude-Code-Alternativen für spezifische Aufgabentypen. Die Wahl von Codex mit GPT-5.5 statt Claude Code durch den Onchain-AI-Garage-Builder für ein visuelles Frontend-Projekt am 29. April 2026 ist ein kleiner, aber bedeutsamer Datenpunkt: Der Builder nannte Claude Code explizit als seinen üblichen Präferenzanbieter und fand die Qualitätslücke nach dem Wechsel schmaler als erwartet. Plattformloyalität erodiert, weil die Plattformen selbst ihre Wertversprechen nicht mehr stabil halten.
Prognose
Die Belege über diese sechs Quellen hinweg, die ein 48-Stunden-Fenster des KI-Intelligence-Zyklus umspannen, deuten auf drei strukturelle Entwicklungen in naher Zukunft hin.
Erstens werden explizite tokenbasierte Preisstufen für Coding- und agentische KI-Tools innerhalb der nächsten 12 Monate zur Norm. Die Flatrate-Stufen von $20, $100 und $200/Monat werden als Markteinstiegs-Preispunkte bestehen bleiben, aber die Obergrenze – der Punkt, an dem Nutzer gedrosselt, zu Überschreitungsabrechnung gerouted oder ein Kontingent-Aufstockungsangebot unterbreitet wird – wird niedriger angesetzt und sichtbarer offengelegt werden. Tim Carambats Prognose vom April 2026, dass eine Max-Stufe für $500/Monat innerhalb von ein bis zwei Monaten erscheinen würde, ist richtungsweisend richtig, unabhängig vom genauen Preispunkt. Die strukturelle Frage ist nicht ob die Preisgestaltung sich ändert, sondern wie transparent dieser Wandel kommuniziert wird und ob die Labs die Umstellung ohne den Vertrauensschaden bewältigen können, den der Hermes.MD-Vorfall verursacht hat.
Zweitens wird die im Claude-Code-Abrechnungsvorfall identifizierte Governance-Lücke strukturelle Kommunikationsänderungen bei Anthropic und wahrscheinlich bei anderen Labs erzwingen, die unter ähnlichem Kostendruck operieren. Der Abrechnungsfehler erzeugte eine rechtliche und reputationsbezogene Exposition, die das Unternehmen zunächst durch informelle Twitter-Versprechen zu lösen suchte, die seinen eigenen Support-Queue-Antworten direkt widersprachen. Eine ernsthafte Sammelklage oder behördliche Beschwerde eines betroffenen Enterprise-Kunden wird dieses Verhalten schneller ändern als jede interne Kulturinitiative. Das Muster der Kommunikation wichtiger Produktrichtlinienentscheidungen über persönliche Social-Media-Accounts einzelner Mitarbeiter ist bei der aktuellen Unternehmensgröße und Bewertungstrajektorie des Unternehmens nicht nachhaltig.
Drittens wird der Wettbewerbsdruck durch lokale und Open-Source-Modelle sich intensivieren statt stabilisieren. Die Zweijahres-Trajektorie von Llama 2 (4K Kontext, Consumer-Hardware unbrauchbar) zu Qwen 3.5 0.8B (128K Kontext, Consumer-Hardware capable) ist eine Vorschau auf den nächsten Zweijahres-Bogen sowohl für Parametereffizienz als auch Ausgabequalität. Labs, die das Compute-Ökonomie-Problem nicht lösen, bevor dieser Bogen die Qualitätslücke schließt, werden ein strukturelles Kundenakquisitionsproblem haben: Nutzer, die aus wirtschaftlichen Gründen zu günstigeren lokalen Alternativen gewechselt sind und die Qualität als ausreichend befunden haben, werden wahrscheinlich nicht zurückkehren, nur weil das geschlossene Modell sich weiter verbessert hat.
Für Unternehmenseinkäufer, die sich heute in diesem Umfeld bewegen, ist die operative Schlussfolgerung dieselbe, unabhängig davon, welche Lab-Ankündigung die Überprüfung ausgelöst hat: Für Routing auslegen, nicht für Loyalität. Die LangChain-Fleet-Agent-Benchmark-Daten, Carambats Nutzungsökonomie-Analyse und Herks Kontingent-Playbook konvergieren alle auf dieselbe Haltung – das geschlossene Frontier-Modell nutzen, wo es Alternativen für die spezifische Aufgabe nachweislich übertrifft; ansonsten standardmäßig auf die günstigste ausreichende Option setzen. Diese Routing-Disziplin ist kein Zugeständnis an die Grenzen der Cloud-KI. Sie ist die richtige Antwort auf ein Preisumfeld, das noch dabei ist, seinen Boden zu finden.


