
Executive Summary
In a 72-hour window spanning April 21–25, 2026, OpenAI and Anthropic each shipped products that individually resembled capability upgrades but together constitute a structural phase shift in how AI systems compose intelligence with action. GPT Image 2 introduced a reasoning loop before pixel generation. Codex transformed into a full OS-level desktop agent that crossed the human baseline on computer-use benchmarks. GPT-5.5 redefined the frontier performance metric from raw benchmark scores to intelligence delivered per output token. Claude Design rendered reasoning directly as editable HTML, bypassing the pixel primitive entirely.
The shared architectural property across all four releases is precise: the reasoning stack moved upstream of the execution primitive. Previously, the relationship between an LLM and a downstream system (image renderer, browser, OS, code interpreter) was connective—a reasoning model produced an artifact that a separate execution layer consumed. These April releases made that relationship integrative: reasoning now coordinates, searches, verifies, and iterates before committing to the output artifact. The execution primitive becomes a rendering format for a completed reasoning trace.
Two metrics signal this generational shift more clearly than benchmark tables. The first is intelligence-per-token: GPT-5.5 achieves a Terminal Bench score of 39.1 at 2,165 output tokens, against GPT-5.4's 34.2 at 4,950 tokens—a 2.5× improvement in intelligence per token delivered at higher absolute performance, even as per-token pricing doubled. The second is the OS World human baseline crossing: Codex's 78.7% score against the 72.4% human baseline is the first confirmation from a general-purpose model that agentic computer use has cleared human-level performance on real desktop tasks.
The downstream consequences for practitioners and platform operators are structural and already compounding. Specification quality—brief writing, constraint documentation, compositional intent—has become the binding leverage constraint. Agent-callable consumption of execution primitives is beginning to exceed human consumption, with economics that favor scale over session experience. And the middleware SaaS layer that priced against human engagement faces compression from both directions.
What's Shifting
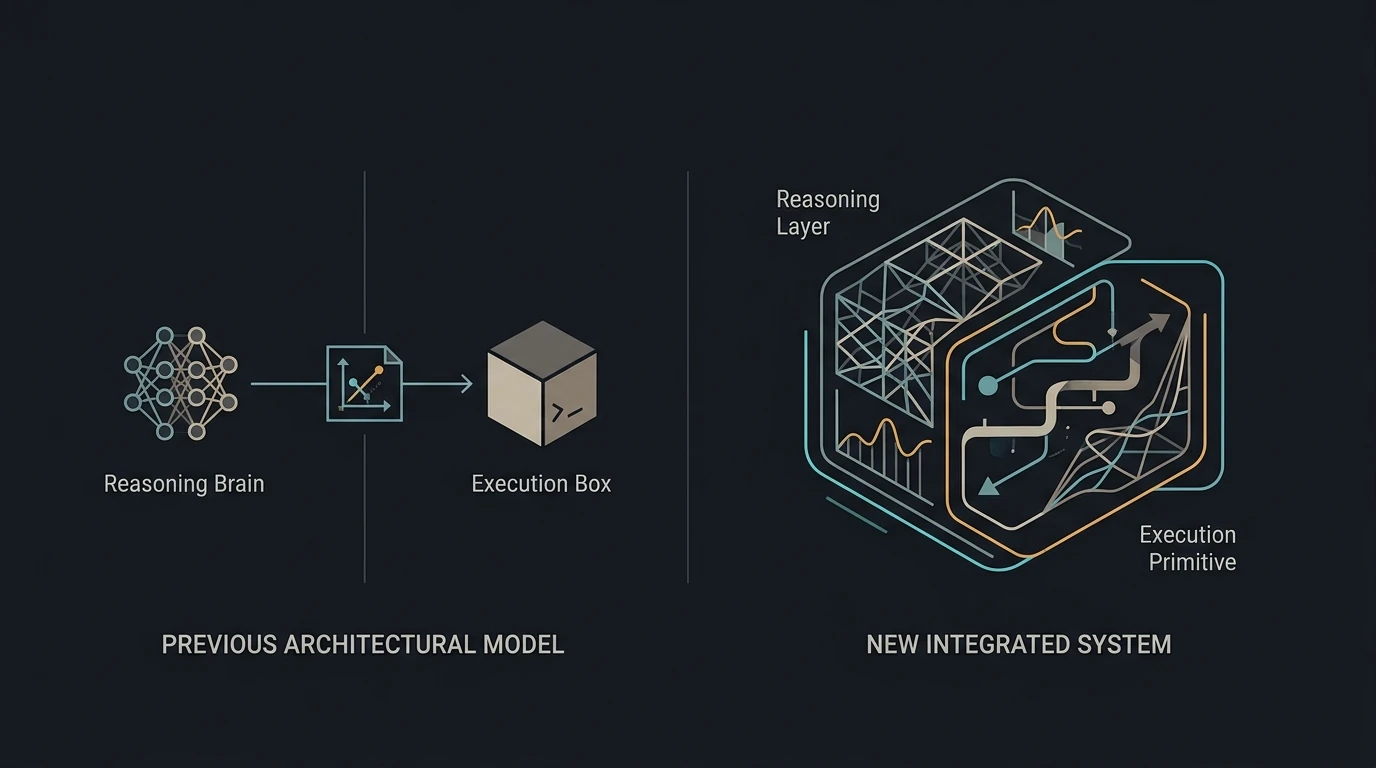
The pre-2026 AI product stack had a consistent architectural property: reasoning and execution were adjacent systems that communicated through artifacts. An LLM produced a text prompt that a diffusion model rendered. An LLM generated JavaScript that a browser executed independently. A reasoning model wrote copy that human designers laid out by hand. The LLM coordinated work; the execution primitives remained separate substrates.
The April 2026 releases dissolved that separation in four places simultaneously, and the mechanism is the same in each case.
GPT Image 2's thinking mode spends 10–20 seconds reasoning through composition, typography hierarchy, object placement, and constraint satisfaction before committing to a pixel. Web search runs inside the generation loop itself: the model can render a geologically accurate depth chart of the Strait of Hormuz in Richard Scarry illustration style by fetching live geologic data mid-generation and fusing it with aesthetic translation in a single pass, as demonstrated in analyst coverage on April 25 (Nate B Jones, YouTube). A self-verification pass re-reads the output against the prompt before returning it—visible in the way typos correct themselves between the first and second generation pass within a single request. The output image is not just pixels; it is a compressed trace of a search-plan-render-verify cycle rendered as an image.
Codex applied the same architectural pattern to OS-level computer use. Background agents on the April 16 desktop release do not hijack cursor focus or interrupt the active window; they run in parallel across the full Mac application surface while the user continues other work. The model understands its own screen state well enough to catch visual regressions autonomously, produce bug reproductions via screenshot-to-PR, and compile daily commits and calendar entries into Notion meeting minutes. OpenAI's October 2025 acquisition of Software Applications Inc.—the Sky team whose lineage runs from Workflow to Apple Shortcuts, and whose members spent cumulative decades at Apple building OS-level integrations—was specifically to obtain this kind of non-model expertise (Nate B Jones, YouTube). Anthropic made a parallel acquisition (Recept) earlier in 2026 for Windows desktop control. Both labs concluded simultaneously that reasoning-capable models needed OS-level bodies, not just API surfaces.
Claude Design, shipped four days before GPT Image 2, arrived at the same architectural destination through a different primitive choice. Rather than adding reasoning upstream of pixels, Anthropic removed the pixel layer entirely: the output is editable HTML that can be handed directly to Claude Code for production. Nate B Jones's analysis frames both launches as downstream of the same underlying insight: reasoning joined the visual stack, and first-draft visual work is now something a reasoning model can execute from long-form context. For rendered assets—posters, menus, product photography, social images—GPT Image 2 is the appropriate output primitive. For working prototypes—landing pages, dashboards, interactive mock-ups—Claude Design's HTML output is already production-ready. Long-term convergence across both branches is likely.
GPT-5.5's token efficiency story completes the picture. Sam Altman's launch thread framing—"to a significant degree, we have to become an AI inference company now"—names the shift precisely: the competitive axis has moved from benchmark ceiling to intelligence per dollar delivered at task (Sam Altman, X/Twitter). swyx, writing on the day of the GPT-5.5 launch, put it directly: "the most underrated part of today's OpenAI launch is the Codex app transformation, not GPT-5.5"—recognizing that the real product story was platform reach, not model capability per se (swyx, X/Twitter).
Evidence
The 26-point arena gap GPT Image 2 achieved over Google Nano Banana 2 (93% vs 67%) is the most unambiguous signal that a step change occurred. Image generation leaderboards historically separate by three to four points; incumbents trade places within a narrow band as incremental improvements compound. A 26-point gap implies architectural divergence, not optimization tuning. Nate B Jones's five-part structural analysis (YouTube) attributes the gap to four specific mechanisms working in concert: the reasoning pre-pass, web search inside the generation loop, eight coherent frames with character continuity from a single prompt, and the self-verification pass. Earlier image generators were direct samplers; GPT Image 2 is a planning-and-execution loop that renders as an image.
Real-world production demonstrations corroborate the benchmark. Takuya Matsuyama, developer of the Inkdrop note-taking app, fed GPT Image 2 app documentation, V6 release notes, and essays he had written about Japanese aesthetics and received back a complete landing page mock-up—Hokusai-inspired hero illustration, wabi-sabi philosophy section cards, feature grid, and typography that reflected the voice and aesthetic philosophy of his written material—from a single prompt. Microsoft Foundry's Zava flower delivery demo assembled a complete ad campaign inside an empty subway car photograph across three prompts, start to finish. These are practitioners solving production tasks, not curated capability demonstrations.
The Codex evidence takes a different form. The 78.7% OS World score against a 72.4% human baseline matters as a threshold signal: GPT-5.5 is the first general-purpose model with native computer use that demonstrably surpasses human performance on real desktop task completion, not just narrow benchmarks (Developers Digest, YouTube). The production workflows reported by early testers substantiate the benchmark: researchers gave GPT-5.5 only a high-level algorithmic idea and received completed experiment sweeps with dashboards and outputs the next morning, no human touching code or terminal. One OpenAI manager wrote publicly: "I can now write CUDA kernels like a pro. I can rely on it to run my research experiments."
GPT-5.5's Terminal Bench numbers provide the cleanest quantification of the intelligence-per-token shift. GPT-5.4 scored 34.2 at an average of 4,950 output tokens. GPT-5.5 scored 39.1 at 2,165 output tokens—both higher absolute score and 56% fewer tokens, yielding a 2.5× improvement in the intelligence-per-token ratio before pricing enters the calculation (Matthew Berman, YouTube). Pricing doubled to $5/M input and $30/M output, but the effective cost-per-task is lower across most workloads because the token reduction exceeds the price increase. The enterprise Box benchmark showed meaningful gains in financial services (+20 points), healthcare (+17 points), and public sector (+13 points) complex-work evaluations.
DeepSeek V4's simultaneous release confirms that the intelligence-per-token efficiency curve is platform-wide rather than OpenAI-specific. Using hybrid Compressed Sparse Attention (CSA) and Heavy Compressed Attention (HCA)—which collapse KV tokens at 4:1 and 128:1 ratios respectively—V4 achieves 1M-token context while consuming 27% of V3.2's FLOPs and 10% of V3.2's KV-cache at the same window size. V4 Pro pricing at $1.74/M input tokens, with cache-hit pricing at $0.14/M, makes it materially competitive with GPT-5.5 on most benchmarks at roughly 35% of the cost. Two independent labs, two independent architectures, converging on the same efficiency direction within the same week.
Countertrends

The architectural objections raised in the same window are substantive and deserve direct engagement rather than dismissal.
Yann LeCun posted on the day of GPT-5.5's launch that building systems with genuine intelligence requires "common sense, the ability to predict the consequences of your actions, the ability to plan, the ability to reason"—and that generative architectures cannot provide these capabilities. The LeWorldModel (LeWM) research published April 24 gives his position empirical grounding: a JEPA-based world model trained from raw pixels achieves 96% planning success at 0.98 seconds versus 78% at 47 seconds for the prior best approach, and it internalizes genuine physical constraints (objects cannot teleport; light falls from sources, not evenly). LeWM requires non-generative architecture—Joint Embedding Predictive Architecture rather than next-token prediction—and it currently operates at 15 million parameters on toy environments, not production scale. The reasoning-stack expansion in this report addresses knowledge work and creative work. LeCun is pointing at a distinct layer: robots, physical automation, and systems that must model causal consequence. Both observations can be simultaneously correct.
Gary Marcus amplified a parallel argument: information technology has not materially changed the architecture of daily life—heating, transport, food, construction—since 1970. The atom-based technologies that actually moved the curve are copper wire, concrete, penicillin, and internal combustion. Code cannot insulate a house; no algorithm has laid a water main. This framing is accurate at the civilizational layer while being a different question than the one GPT Image 2 and Codex answer. The products in this report operate on knowledge work and creative work, where the disruption curve is already steep and the economic impact is measurable in the near term.
The LLM Fallacy paper, surfaced by AlphaSignal on April 23, introduces an operationally immediate countertrend: when AI output is fluent, users unconsciously credit themselves for it, inflating confidence while real skill quietly erodes. The paper documents the pattern across four domains—coding, writing, analysis, and language acquisition—and frames it as "the GPS effect applied to your entire career." This is worth taking seriously precisely because it is the flip side of the specification-skill argument: the same shift that elevates brief quality as the binding constraint also creates a failure mode where practitioners mistake prompt-fluency for genuine capability development. Organizations building AI augmentation workflows need explicit mechanisms for preserving practitioner skill density, not just output velocity.
Cost discipline is uneven across workload types. GPT-5.5 at 13 cents per page on ParseBench OCR at mid-thinking mode is five times more expensive than LlamaParse at 1.25 cents per page. The intelligence-per-token argument transfers to tasks that require reasoning complexity; it does not uniformly close the cost-to-value gap for commodity workloads where simpler, cheaper tools already deliver adequate accuracy. Task specificity is required before efficiency claims transfer from benchmark tables to operating budgets.
Personal-AI disillusionment, documented candidly by Kitze at the AI Engineer Europe conference on April 23, is a leading indicator of reliability gaps that persist below the model capability layer. Tinkerer-class OpenClaw adoption has hit walls not in model intelligence but in multi-agent orchestration reliability, UI surface fitness (Discord and Telegram were not built for agent management), and the friction of life-OS data entry. Ethan Mollick flagged the same gap from a research angle: "organizational design for agents AND benchmarking multi-agent systems are the next critical frontier for economic AI impact—we really don't know very much about it." Reasoning moving upstream of primitives is necessary but not sufficient; the coordination layer between multiple reasoning-upstream agents remains an open problem.
Forecast
The primitive expansion will continue on a predictable trajectory. Reasoning is now structurally upstream of pixels (GPT Image 2), editable code (Claude Design), OS-level actions (Codex), and general inference (GPT-5.5). Audio, video, 3D mesh, and sensor-data primitives are next in the integration sequence. Veo and emerging spatial computing frameworks are on the same path: reasoning will coordinate their outputs before a single frame is committed to storage. The four April 2026 products are not endpoints; they are the first confirmed instances of a structural pattern that will extend across all digital execution surfaces within 18 to 24 months.
Specification layer growth is structural and durable. When reasoning moves upstream of execution, practitioner leverage migrates with it. The brief, the constraint document, the brand system reference, the compositional intent memo—these are what differentiate outputs when first-draft execution is automated. This is the same occupational migration that word processors imposed on typesetters and web browsers imposed on publishers: the layer requiring human judgment moves upstream while the mechanical execution layer compresses. The practitioners positioned ahead are those who already think in explicit constraints, reference assets, typography rules, and compositional intent. Those whose value lived in execution craft face migration pressure, not elimination.
Agent-callable consumption will exceed human-directed consumption faster than current product roadmaps acknowledge. The visible market for image generation is human-driven design work; this is what product marketing addresses. The invisible market—agent harnesses (Conway, Hermes, Codex workflows) invoking image generation as a computational subroutine inside automated pipelines—will scale faster because its economics are structurally different: latency tolerance is higher, per-image pricing matters more than session UX, and many generated artifacts are never seen by a human, flowing directly into the next agentic step. Middleware SaaS vendors that priced against a large surface area of human engagement are exposed to compression from both the platform layer (OpenAI and Anthropic providing native capability) and the agent layer (automation eliminating the human engagement assumption).
Token efficiency will become the primary competitive axis as the frontier capability gap narrows. DeepSeek V4 Flash at $0.14/M input and GPT-5.5 at $5/M demonstrate that the price-to-intelligence range across credible frontier options now spans more than 30×. Multi-model routing—deploying different models for different task tiers based on intelligence-per-dollar—is already practiced by sophisticated teams and will become baseline infrastructure as the cost-performance curve fragments across providers. The question "which model is smartest?" will increasingly be displaced by "which model delivers sufficient intelligence per dollar at this specific task tier?"
The trust-stack remediation gap is the most consequential open-problem opportunity this window has revealed. GPT Image 2 at 99% in-image text accuracy, with December 2025 web knowledge and live search capability, achieved above 70% "real photo" pass rates in blind arena tests across forged receipts, Slack screenshots, boarding passes, pharmacy labels, and government notices. Content credentials do not survive a screenshot recrop, and they never have. Journalism fact-check infrastructure, KYC vendors, insurance fraud detection, customs authorities, and legal discovery workflows are all operating on evidence-trust assumptions that no longer hold. The image-verification layer has no adequate incumbent, and the need will generate significant institutional and commercial investment through 2026 and beyond. The company that builds reliable chain-of-custody verification for visual evidence in the post-GPT-Image-2 environment is one of the better-defined product opportunities of the current cycle.


